 Introduction to Linux interfaces for virtual networking Introduction to Linux interfaces for virtual networking
Introduction to Linux interfaces for virtual networking Introduction to Linux interfaces for virtual networking Linux possède de riches capacités de mise en réseau virtuelle qui servent de base pour l'hébergement de machines virtuelles et de conteneurs, ainsi que d'environnements en nuage. Dans cet article, je vais présenter brièvement tous les types d'interfaces de réseau virtuel couramment utilisés. Il n'y a pas d'analyse de code, mais seulement une brève introduction aux interfaces et à leur utilisation sous Linux. Toute personne ayant une expérience des réseaux pourrait être intéressée par cet article de blog. Une liste des interfaces peut être obtenue en utilisant la commande ip link help.
Ce billet couvre les interfaces suivantes, fréquemment utilisées, et certaines interfaces qui peuvent facilement être confondues entre elles :
Bonded interface (Interface liée)
Team device (Dispositif d'équipe)
Dummy interface (Interface factice)
Bridge
Interface liée
Dispositif d'équipe
VLAN (réseau local virtuel)
VXLAN (Virtual eXtensible Local Area Network)
MACVLAN
IPVLAN
MACVTAP/IPVTAP
MACsec (Sécurité du contrôle d'accès aux médias)
VETH (Ethernet virtuel)
VCAN (CAN virtuel)
VXCAN (tunnel CAN virtuel)
IPOIB (IP-over-InfiniBand)
NLMON (NetLink MONitor)
Interface factice
IFB (Intermediate Functional Block)
netdevsim
Après avoir lu cet article, vous saurez ce que sont ces interfaces, quelle est la différence entre elles, quand les utiliser et comment les créer.
Pour d'autres interfaces comme le tunnel, veuillez consulter An introduction to Linux virtual interfaces: Tunnels
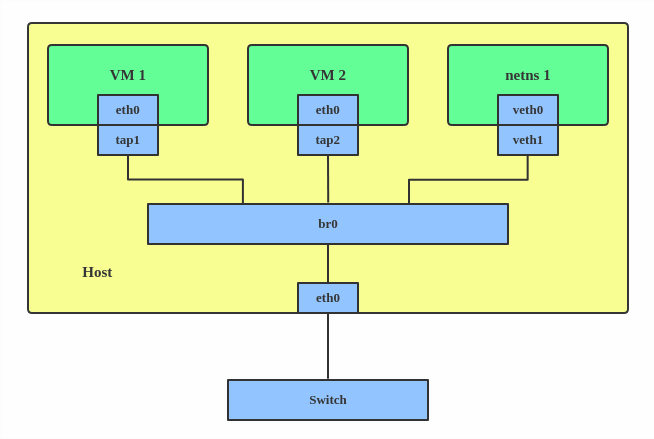
Un pont Linux se comporte comme un commutateur de réseau. Il transmet les paquets entre les interfaces qui lui sont connectées. Il est généralement utilisé pour faire suivre des paquets sur des routeurs, sur des passerelles, ou entre des machines virtuelles et des espaces de noms de réseau sur un hôte. Il prend également en charge le STP, le filtre VLAN et l'espionnage multicast.
Utilisez un pont lorsque vous souhaitez établir des canaux de communication entre les VM, les conteneurs et vos hôtes.
Voici comment créer un pont :
# ip link add br0 type bridge
# ip link set eth0 master br0
# ip link set tap1 master br0
# ip link set tap2 master br0
# ip link set veth1 master br0
Cela crée un dispositif de pont appelé br0 et définit deux dispositifs TAP (tap1, tap2), un dispositif VETH (veth1) et un dispositif physique (eth0) comme ses esclaves, comme le montre le schéma ci-dessus.
Le pilote de liaison Linux fournit une méthode pour agréger plusieurs interfaces réseau en une seule interface logique "liée". Le comportement de l'interface liée dépend du mode ; en général, les modes fournissent soit des services de veille à chaud, soit des services d'équilibrage de charge.
Utilisez une interface liée lorsque vous souhaitez augmenter la vitesse de votre lien ou faire un basculement sur votre serveur.
Voici comment créer une interface liée :
ip link add bond1 type bond miimon 100 mode active-backup
ip link set eth0 master bond1
ip link set eth1 master bond1
Cela crée une interface bondée appelée bond1 avec un mode de sauvegarde actif. Pour les autres modes, veuillez consulter la kernel documentation.
Semblable à une interface liée, le but d'un dispositif d'équipe est de fournir un mécanisme permettant de regrouper plusieurs NIC (ports) en une seule logique (teamdev) au niveau de la couche L2.
La principale chose à réaliser est qu'un dispositif d'équipe n'essaie pas de reproduire ou d'imiter une interface liée. Ce qu'il fait, c'est résoudre le même problème en utilisant une approche différente, par exemple en utilisant une voie TX/RX sans verrouillage (RCU) et une conception modulaire.
Mais il existe également des différences fonctionnelles entre une interface liée et une équipe. Par exemple, une équipe prend en charge l'équilibrage de charge LACP, la surveillance des liaisons NS/NA (IPV6), l'interface D-Bus, etc. qui sont absents dans le collage. Pour plus de détails sur les différences entre le bonding et l'équipe, voir Bonding vs. Team features.
Utilisez une équipe lorsque vous souhaitez utiliser certaines fonctionnalités que le bonding ne fournit pas.
Voici comment créer une équipe :
# teamd -o -n -U -d -t team0 -c '{"runner": {"name": "activebackup"},"link_watch": {"name": "ethtool"}}'
# ip link set eth0 down
# ip link set eth1 down
# teamdctl team0 port add eth0
# teamdctl team0 port add eth1
Cela crée une interface d'équipe appelée team0 avec un mode de sauvegarde actif, et ajoute eth0 et eth1 comme sous-interfaces de team0.
Un nouveau pilote appelé net_failover a été ajouté à Linux récemment. Il s'agit d'un autre périphérique réseau maître de basculement pour la virtualisation et il gère un périphérique réseau esclave primaire (passthru/VF [Virtual Function] device) et un périphérique réseau esclave de secours (l'interface paravirtuelle d'origine).
Un VLAN, ou réseau local virtuel, sépare les domaines de diffusion en ajoutant des balises aux paquets du réseau. Les VLAN permettent aux administrateurs réseau de regrouper des hôtes sous un même commutateur ou entre différents commutateurs.
L'en-tête du VLAN ressemble à :
Utilisez un VLAN lorsque vous souhaitez séparer un sous-réseau en VM, espaces de noms ou hôtes.
Voici comment créer un VLAN :
# ip link add link eth0 name eth0.2 type vlan id 2
# ip link add link eth0 name eth0.3 type vlan id 3
Cela ajoute le VLAN 2 avec le nom eth0.2 et le VLAN 3 avec le nom eth0.3. La topologie ressemble à ceci :
Remarque : lors de la configuration d'un VLAN, vous devez vous assurer que le commutateur connecté à l'hôte est capable de gérer les balises VLAN, par exemple en réglant le port du commutateur en mode "trunk".
VXLAN (Virtual eXtensible Local Area Network) est un protocole de tunneling conçu pour résoudre le problème des ID VLAN limités (4 096) dans l'IEEE 802.1q. Il est décrit par IETF RFC 7348.
Avec un ID de segment de 24 bits, alias VXLAN Network Identifier (VNI), VXLAN permet de créer jusqu'à 2^24 (16 777 216) réseaux locaux virtuels, soit 4 096 fois la capacité du VLAN.
Le VXLAN encapsule les trames de la couche 2 avec un en-tête VXLAN dans un paquet UDP-IP, qui ressemble à ceci :
Le VXLAN est généralement déployé dans des centres de données sur des hôtes virtualisés, qui peuvent être répartis sur plusieurs baies.
Voici comment utiliser VXLAN :
# ip link add vx0 type vxlan id 100 local 1.1.1.1 remote 2.2.2.2 dev eth0 dstport 4789
Pour référence, vous pouvez lire la VXLAN kernel documentation ou this VXLAN introduction.
Avec le VLAN, vous pouvez créer plusieurs interfaces en plus d'une seule et filtrer les paquets en fonction d'une balise VLAN. Avec MACVLAN, vous pouvez créer plusieurs interfaces avec différentes adresses de couche 2 (c'est-à-dire Ethernet MAC) sur une seule.
Avant MACVLAN, si vous vouliez vous connecter à un réseau physique à partir d'une VM ou d'un espace de noms, vous auriez dû créer des périphériques TAP/VETH et en attacher un côté à un pont et attacher une interface physique au pont sur l'hôte en même temps, comme indiqué ci-dessous..
Maintenant, avec MACVLAN, vous pouvez lier une interface physique associée à un MACVLAN directement à des espaces de noms, sans avoir besoin d'un pont.
Il existe cinq types de MACVLAN :
1. Privé : ne permet pas la communication entre les instances MACVLAN sur la même interface physique, même si le commutateur externe supporte le mode épingle à cheveux.
2. VEPA : les données d'une instance MACVLAN à l'autre sur la même interface physique sont transmises sur l'interface physique. Soit le commutateur attaché doit supporter le mode épingle à cheveux, soit il doit y avoir un routeur TCP/IP qui transmet les paquets afin de permettre la communication.
3. Pont : tous les points terminaux sont directement reliés entre eux par un simple pont via l'interface physique.
4. Passthru : permet de connecter une seule VM directement à l'interface physique.
5. Source : le mode source est utilisé pour filtrer le trafic sur la base d'une liste d'adresses MAC sources autorisées afin de créer des associations VLAN basées sur les MAC. Veuillez consulter le message de validation.
Le type est choisi en fonction des différents besoins. Le mode pont est le plus utilisé.
Utilisez un MACVLAN lorsque vous souhaitez vous connecter directement à un réseau physique à partir de conteneurs.
Voici comment mettre en place un MACVLAN :
# ip link add macvlan1 link eth0 type macvlan mode bridge
# ip link add macvlan2 link eth0 type macvlan mode bridge
# ip netns add net1
# ip netns add net2
# ip link set macvlan1 netns net1
# ip link set macvlan2 netns net2
Cela permet de créer deux nouveaux appareils MACVLAN en mode pont et d'assigner ces deux appareils à deux espaces de noms différents.
Le réseau IPVLAN est similaire au réseau MACVLAN, à la différence que les points terminaux ont la même adresse MAC.
L'IPVLAN prend en charge les modes L2 et L3. Le mode L2 de l'IPVLAN agit comme un MACVLAN en mode pont. L'interface parent ressemble à un pont ou à un commutateur.
En mode IPVLAN L3, l'interface parent agit comme un routeur et les paquets sont acheminés entre les points d'extrémité, ce qui donne une meilleure évolutivité.
En ce qui concerne le moment où il faut utiliser un IPVLAN, la IPVLAN kernel documentation indique que le MACVLAN et l'IPVLAN "sont très similaires à bien des égards et le cas d'utilisation spécifique pourrait très bien définir le périphérique à choisir. Si l'une des situations suivantes définit votre cas d'utilisation, vous pouvez alors choisir d'utiliser l'ipvlan -
(a) L'hôte Linux qui est connecté au commutateur / routeur externe a une configuration de politique qui n'autorise qu'un seul mac par port.
(b) Aucun des dispositifs virtuels créés sur un maître ne dépasse la capacité du mac et met le NIC en mode de promiscuité et la dégradation des performances est préoccupante.
(c) Si le dispositif esclave doit être placé dans l'espace de noms du réseau hostile / non fiable où L2 sur l'esclave pourrait être changé / mal utilisé".
Voici comment mettre en place une instance IPVLAN :
# ip netns add ns0
# ip link add name ipvl0 link eth0 type ipvlan mode l2
# ip link set dev ipvl0 netns ns0
This creates an IPVLAN device named ipvl0 with mode L2, assigned to namespace ns0.
MACVTAP/IPVTAP est un nouveau pilote de périphérique destiné à simplifier la mise en réseau pontée virtualisée. Lorsqu'une instance MACVTAP/IPVTAP est créée au-dessus d'une interface physique, le noyau crée également un périphérique de caractères/dev/tapX à utiliser comme un périphérique TUN/TAP qui peut être directement utilisé par KVM/QEMU.
Avec MACVTAP/IPVTAP, vous pouvez remplacer la combinaison des pilotes TUN/TAP et de pont par un seul module :
En général, le MACVLAN/IPVLAN est utilisé pour faire apparaître l'invité et l'hôte directement sur le commutateur auquel l'hôte est connecté. La différence entre MACVTAP et IPVTAP est la même que pour MACVLAN/IPVLAN.
Voici comment créer une instance MACVTAP :
# ip link add link eth0 name macvtap0 type macvtap
MACsec (Media Access Control Security) est une norme de l'IEEE pour la sécurité des réseaux locaux Ethernet câblés. Semblable à IPsec, en tant que spécification de couche 2, MACsec peut protéger non seulement le trafic IP, mais aussi l'ARP, la découverte des voisins et le DHCP. Les en-têtes MACsec ressemblent à ceci :
Le principal cas d'utilisation de MACsec est la sécurisation de tous les messages sur un réseau local standard, y compris les messages ARP, NS et DHCP.
Voici comment mettre en place une configuration MACsec :
# ip link add macsec0 link eth1 type macsec
Note : Ceci ajoute seulement un dispositif MACsec appelé macsec0 sur l'interface eth1. Pour des configurations plus détaillées, veuillez consulter la section “Configuration example” dans MACsec introduction by Sabrina Dubroca.
Le dispositif VETH (virtual Ethernet) est un tunnel Ethernet local. Les dispositifs sont créés par paires, comme le montre le schéma ci-dessous.
Les paquets transmis sur un dispositif de la paire sont immédiatement reçus sur l'autre dispositif. Lorsque l'un des dispositifs est hors service, l'état de la liaison de la paire est hors service.
Utilisez une configuration VETH lorsque les espaces de noms doivent communiquer avec l'espace de noms principal de l'hôte ou entre eux.
Voici comment mettre en place une configuration VETH :
# ip netns add net1
# ip netns add net2
# ip link add veth1 netns net1 type veth peer name veth2 netns net2
Cela crée deux espaces de noms, net1 et net2, et une paire de dispositifs VETH, et cela affecte veth1 à l'espace de noms net1 et veth2 à l'espace de noms net2. Ces deux espaces de noms sont reliés à cette paire de VETH. Attribuez une paire d'adresses IP, et vous pouvez faire un ping et communiquer entre les deux espaces de noms.
Tout comme les dispositifs de bouclage du réseau, le pilote VCAN (virtual CAN) offre une interface CAN (Controller Area Network) locale virtuelle, de sorte que les utilisateurs peuvent envoyer/recevoir des messages CAN via une interface VCAN. Le CAN est principalement utilisé dans le domaine de l'automobile de nos jours.
Pour plus d'informations sur le protocole CAN, veuillez vous référer à la kernel CAN documentation.
Utilisez un VCAN lorsque vous souhaitez tester une implémentation du protocole CAN sur l'hôte local.
Voici comment créer un VCAN :
# ip link add dev vcan1 type vcan
Tout comme le pilote VETH, un VXCAN (Virtual CAN tunnel) met en œuvre un tunnel de trafic CAN local entre deux périphériques du réseau VCAN. Lorsque vous créez une instance VXCAN, deux dispositifs VXCAN sont créés en tant que paire. Lorsqu'une extrémité reçoit le paquet, celui-ci apparaît sur la paire de périphériques et vice versa. VXCAN peut être utilisé pour la communication entre espaces de noms.
Utilisez une configuration VXCAN lorsque vous souhaitez envoyer un message CAN à travers des espaces de noms.
Voici comment configurer une instance VXCAN :
# ip netns add net1
# ip netns add net2
# ip link add vxcan1 netns net1 type vxcan peer name vxcan2 netns net2
Remarque : VXCAN n'est pas encore pris en charge par Red Hat Enterprise Linux.
Un dispositif IPOIB prend en charge le protocole IP-over-InfiniBand. Celui-ci transporte les paquets IP sur InfiniBand (IB) afin que vous puissiez utiliser votre appareil IB comme une carte d'interface réseau rapide.
Le pilote IPoIB prend en charge deux modes de fonctionnement : datagramme et connecté. En mode datagramme, le transport IB UD (Unreliable Datagram) est utilisé. En mode connecté, le transport IB RC (Reliable Connecté) est utilisé. Le mode connecté profite de la nature connectée du transport IB et permet une MTU jusqu'à la taille maximale de paquet IP de 64K.
Pour plus de détails, veuillez consulter la IPOIB kernel documentation.
Utilisez un dispositif IPOIB lorsque vous disposez d'un dispositif IB et que vous souhaitez communiquer avec un hôte distant via IP.
Voici comment créer un périphérique IPOIB :
# ip link add ib0 name ipoib0 type ipoib pkey IB_PKEY mode connected
NLMON est un dispositif de surveillance Netlink.
Utilisez un appareil NLMON lorsque vous souhaitez surveiller les messages Netlink du système.
Voici comment créer un dispositif NLMON :
# ip link add nlmon0 type nlmon
# ip link set nlmon0 up
# tcpdump -i nlmon0 -w nlmsg.pcap
Cela crée un dispositif NLMON appelé nlmon0 et le met en place. Utilisez un renifleur de paquets (par exemple, tcpdump) pour capturer les messages Netlink. Les versions récentes de Wireshark permettent le décodage des messages Netlink.
Une interface factice est entièrement virtuelle comme, par exemple, l'interface en boucle. L'objectif d'une interface factice est de fournir un dispositif permettant d'acheminer des paquets sans les transmettre réellement.
Utilisez une interface factice pour faire en sorte qu'une adresse SLIP (Serial Line Internet Protocol) inactive ressemble à une adresse réelle pour des programmes locaux. De nos jours, une interface factice est surtout utilisée pour les tests et le débogage.
Voici comment créer une interface factice :
# ip link add dummy1 type dummy
# ip addr add 1.1.1.1/24 dev dummy1
# ip link set dummy1 up
Le conducteur IFB (Intermediate Functional Block) fournit un dispositif qui permet de concentrer le trafic provenant de plusieurs sources et de modeler le trafic entrant au lieu de le laisser tomber.
Utilisez une interface IFB lorsque vous voulez faire la queue et modeler le trafic entrant.
Voici comment créer une interface IFB :
# ip link add ifb0 type ifb
# ip link set ifb0 up
# tc qdisc add dev ifb0 root sfq
# tc qdisc add dev eth0 handle ffff: ingress
# tc filter add dev eth0 parent ffff: u32 match u32 0 0 action mirred egress redirect dev ifb0
Cela crée un dispositif IFB nommé ifb0 et remplace l'ordonnanceur qdisc racine par SFQ (Stochastic Fairness Queueing), qui est un ordonnanceur de file d'attente sans classe. Ensuite, il ajoute un ordonnanceur de disques d'entrée (ingress qdisc scheduler) sur eth0 et redirige tout le trafic d'entrée vers ifb0.
Pour plus de cas d'utilisation de qdisc IFB, veuillez vous référer à Linux Foundation wiki on IFB.
•.Virtual networking articles on the Red Hat Developer blog
•.Dynamic IP Address Management in Open Virtual Network (OVN)
•.Open vSwitch articles on the Red hat Developer Blog
netdevsim est un appareil de réseautage simulé qui est utilisé pour tester différentes API de réseautage. Actuellement, il est particulièrement axé sur le test de matériel
déchargement, tc/XDP BPF et SR-IOV.
Un dispositif netdevsim peut être créé comme suit
# ip link add dev sim0 type netdevsim
# ip link set dev sim0 up
Pour permettre le déchargement de tc :
# ethtool -K sim0 hw-tc-offload on
Pour charger les programmes XDP BPF ou tc BPF :
# ip link set dev sim0 xdpoffload obj prog.o
Pour ajouter des VFs pour les tests SR-IOV :
# echo 3 > /sys/class/net/sim0/device/sriov_numvfs
# ip link set sim0 vf 0 mac
Pour changer les numéros de vf, vous devez d'abord les désactiver complètement :
# echo 0 > /sys/class/net/sim0/device/sriov_numvfs
# echo 5 > /sys/class/net/sim0/device/sriov_numvfs
Note : netdevsim n'est pas compilé dans RHEL par défaut
 Bridge diagram
Bridge diagram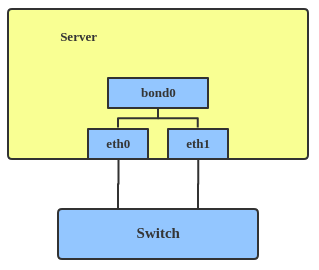 Bonded interface
Bonded interface Team device
Team device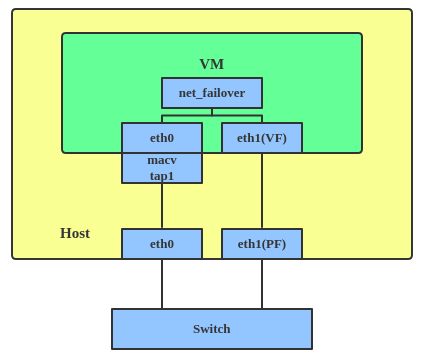 Net_failover driver
Net_failover driver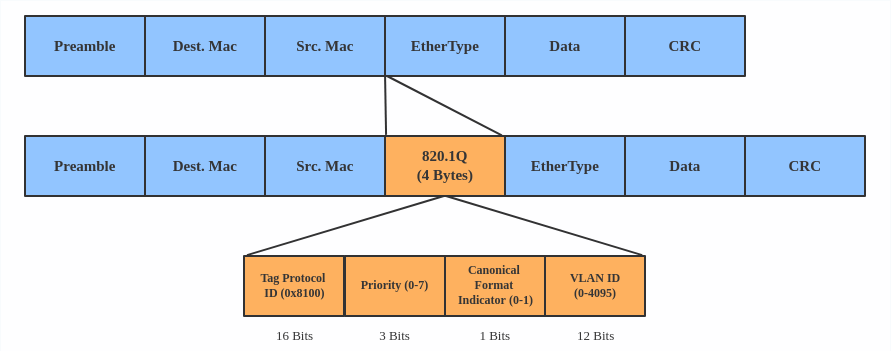 VLAN header
VLAN header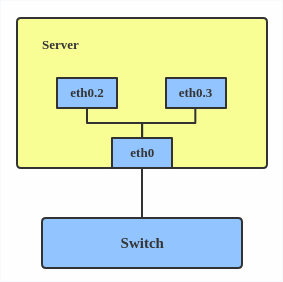 VLAN topology
VLAN topology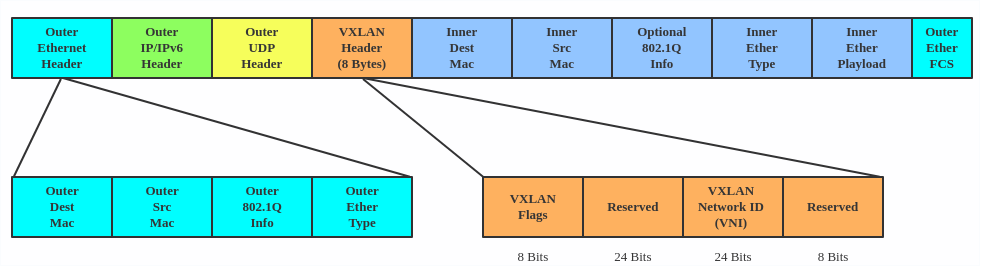 VXLAN encapsulates Layer 2 frames with a VXLAN header into a UDP-IP packet
VXLAN encapsulates Layer 2 frames with a VXLAN header into a UDP-IP packet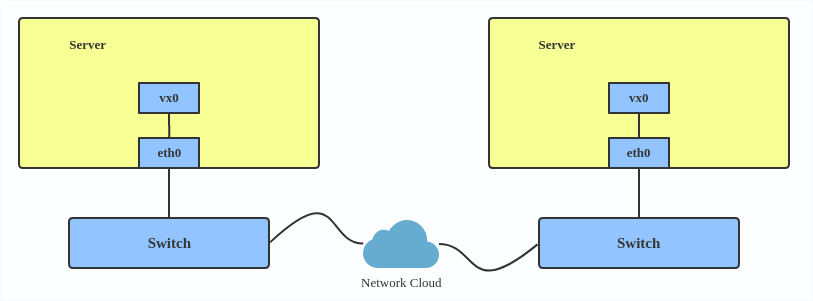 Typical VXLAN deployment
Typical VXLAN deployment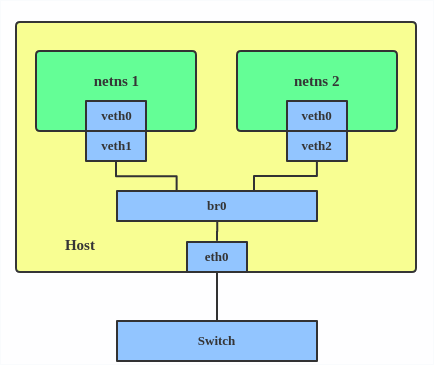 Configuration before MACVLAN
Configuration before MACVLAN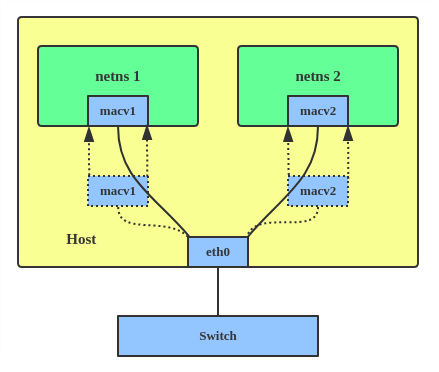 Configuration with MACVLAN
Configuration with MACVLAN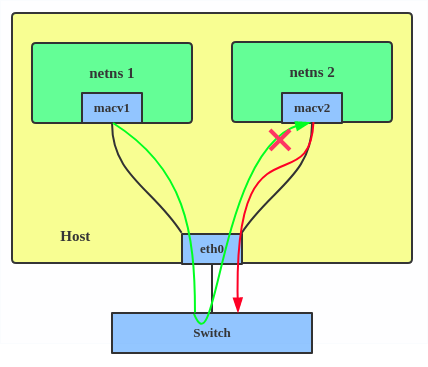 Private MACVLAN configuration
Private MACVLAN configuration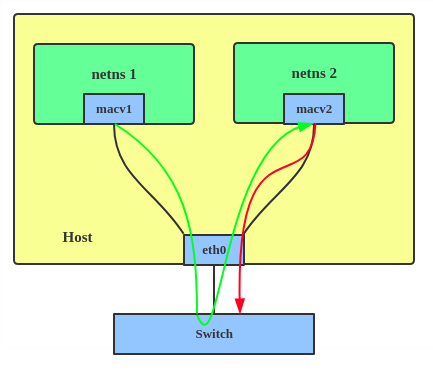 VEPA MACVLAN configuration
VEPA MACVLAN configuration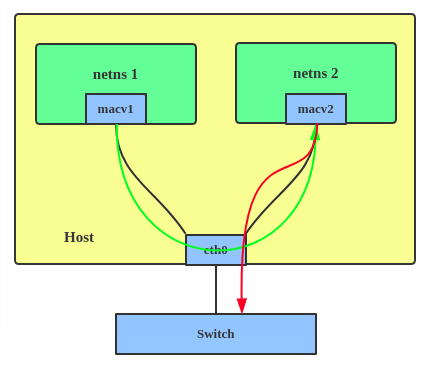 Bridge MACVLAN configuration
Bridge MACVLAN configuration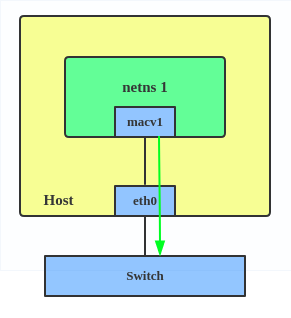 Passthru MACVLAN configuration
Passthru MACVLAN configuration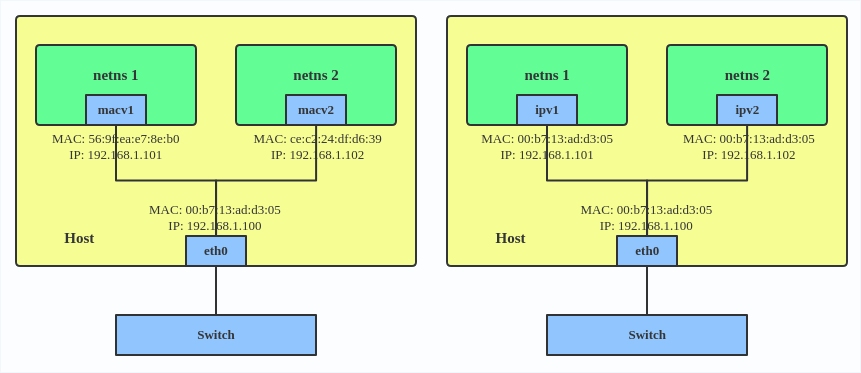 IPVLAN configuration
IPVLAN configuration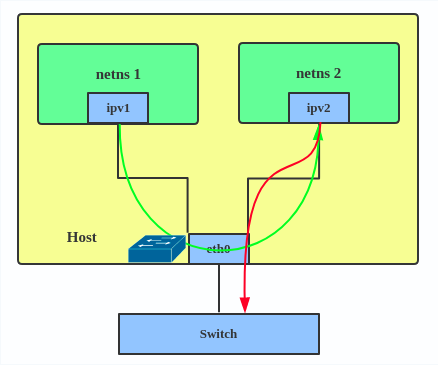 IPVLAN L2 mode
IPVLAN L2 mode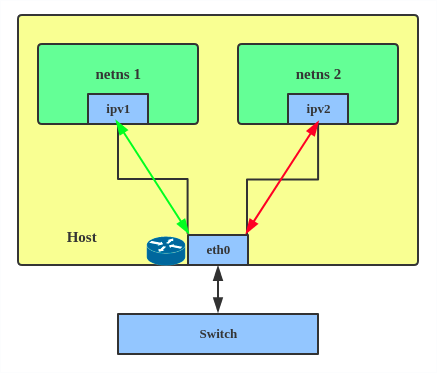 IPVLAN L3 mode
IPVLAN L3 mode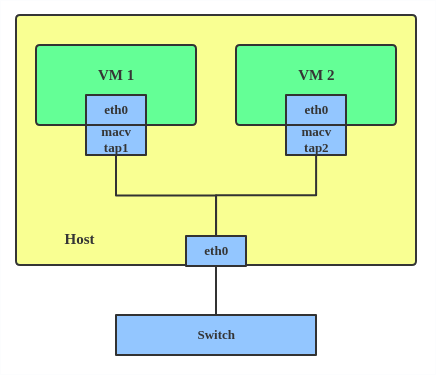 MACVTAP/IPVTAP instance
MACVTAP/IPVTAP instance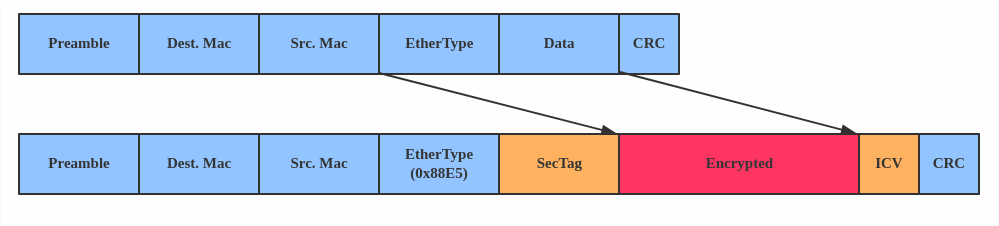 MACsec header
MACsec header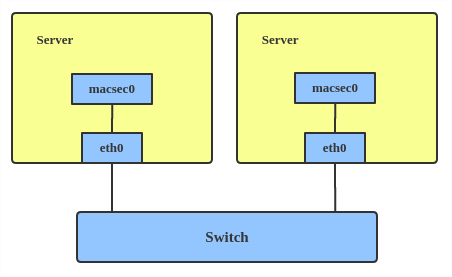 MACsec configuration
MACsec configuration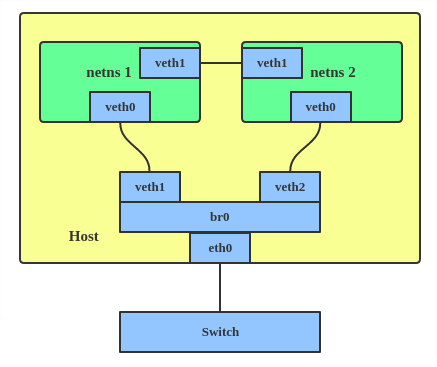 Pair of VETH devices
Pair of VETH devices